
ก่อนจะไปดูเรื่องของ Caching เรามาดูภาพรวมของการจัดการเกี่ยวกับ Performance ของ System Architecture อย่างง่ายกันก่อน
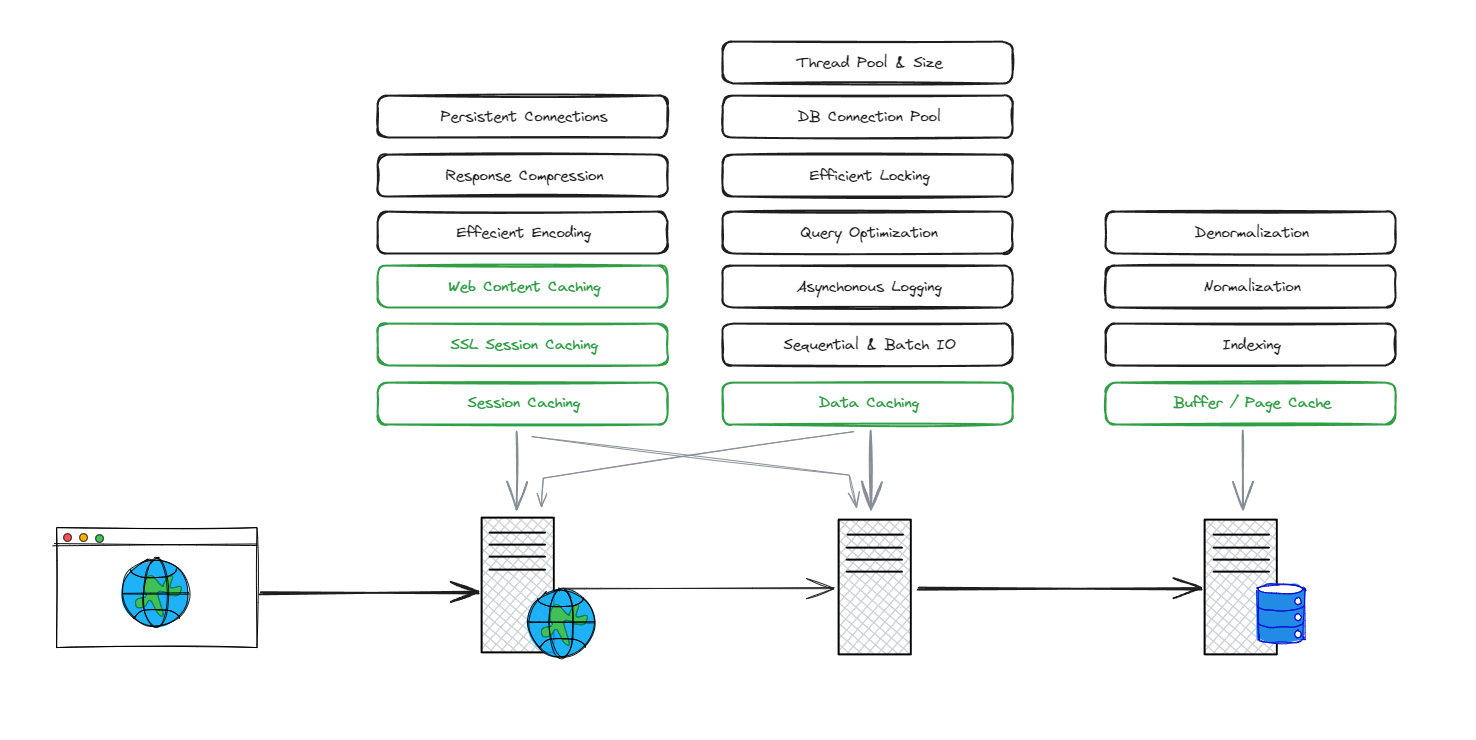
จะเห็นได้ว่า แต่ละส่วนนั้น เราต้องใส่ใจและสามารถ Optimize มันได้ประมาณนี้ ซึ่งจะสังเกตได้ว่า เมื่อในทุกๆ Server แต่ละตัวนั้น จะมีเรื่องของการทำ Caching ประกอบอยู่ด้วยเสมอ
ดังนั้นเรามาดูเรื่องของ Caching กัน
Caching for Performance
เริ่มต้นที่ สมมติว่าเรามี architecture ประมาณนั้น
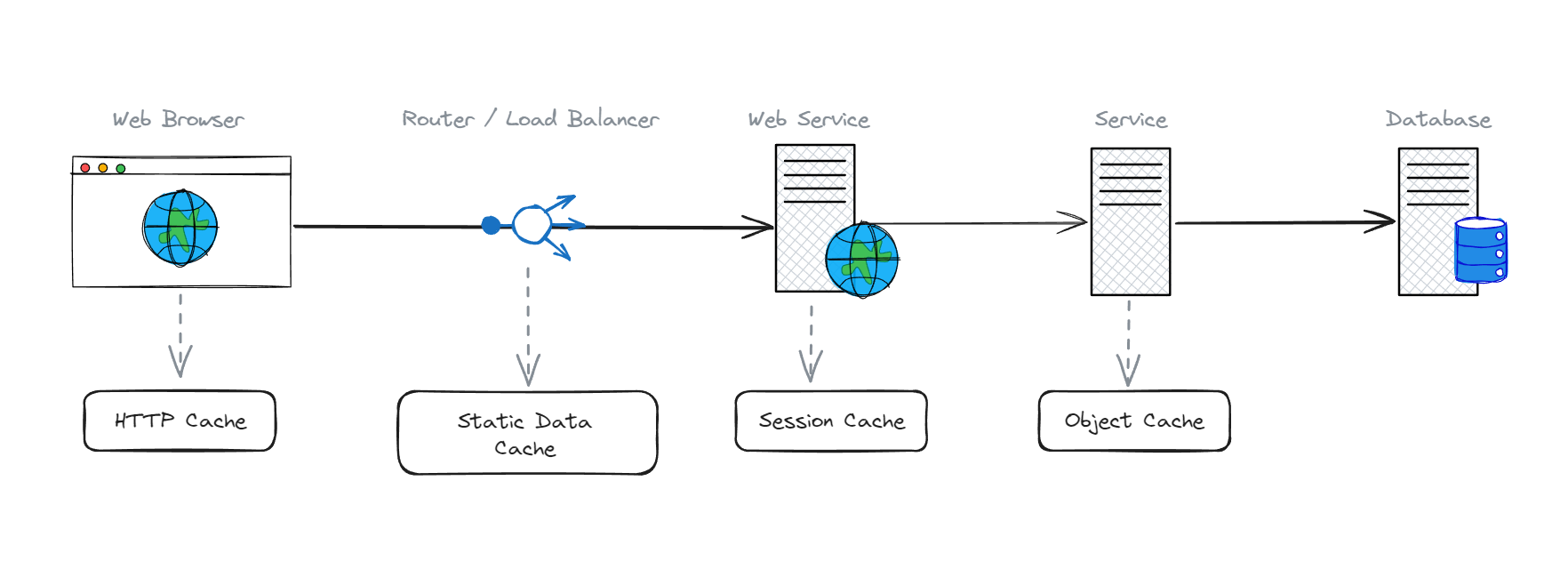
จะเห็นว่า ในแต่ละส่วนนั้น เราสามารถที่จะทำ caching ได้หมดเลย
เริ่มจาก...
ระดับของ Service/APIs Service
เมื่อไหร่ก็ตามที่เราไปดึงข้อมูลจาก database เราสามารถ caching ข้อมูลเหล่านั้นไว้บน server ของเราได้ โดยที่เราจะสนใจข้อมูลที่มีการใช้งานร่วมกัน (พยายามหลีกเลี่ยงการ cache ข้อมูลที่เป็นข้อมูลเฉพาะของ user)
ทำให้หลังจากที่เราทำการ cache ไว้แล้ว หลังจากนั้น เราจะเรียกใช้งานจาก cache ได้เลย โดยที่ไม่จำเป็นต้องไป query จาก database ใหม่ทุกรอบ
ระดับของ Web Service / Web Application
ส่วนนี้ข้อมูลที่จะเรียกใช้ส่วนใหญ่จะเป็นข้อมูลของ user ดั้งนั้นหากข้อมูลไหนถูกเรียกใช้งานบ่อยๆ เราสามารถเอามันไปเก็บไว้ใน session ได้ โดยเราอาจโฟกัสไปที่ข้อมูลที่เป็น particular data (ข้อมูลเฉพาะ) ที่เชื่อมโยงกับ session ของ user เช่น user profile
อีกทั้งเรายังสามารถ cache ข้อมูลที่เป็น dynamic data ด้วยก็ได้ ถ้าหากข้อมูลนั้นไม่มีการอัพเดทบ่อยมากนัก และมีการ request บ่อยๆ แต่ถ้าหากข้อมูลอัพเดทบ่อยเกินไป เราก็จะไม่ cache ข้อมูลนั้น เนื่องจากว่ามันไม่ค่อยมีประโยชน์เท่าไหร่
ข้อมูลที่ควร cache ไว้เลย คือ ข้อมูลคงที่ต่างๆ เช่น ไฟล์รูปภาพ, javascript, css, html เป็นต้น ส่วนใหญ่ไฟล์เหล่านี้มักจะไม่มีการเปลี่ยนแปลงบ่อยเท่ากับข้อมูลที่เรียกจาก service ดังนั้น ถ้าหากไฟล์ไหนถูเรียกใช้งานบ่อยๆ และไม่ค่อยมีการเปลี่ยนแปลงบ่อยมากนัก ก็โยนเข้า cache โลด
ระดับของ Proxy / Load Balancer
ถ้าเราเข้าใจเรื่องของลักษณะข้อมูลที่ต้อง cache แล้ว เราก็พอจะเดาได้แล้วว่า ในระดับนี้เราสามารถ cache อะไรไว้ได้แล้วบ้าง ซึ่งมันสามารถ cache ได้หลายอย่างเลย โดยเฉพาะ ข้อมูลที่เป็น static content (data/file) เช่น รูปภาพ โดยเราจะ cache มันไว้ที่ CDN หรือจะเอาไปเก็บไว้ใน public cache อื่นๆ
ระดับของ Web Browser / Client
ในระดับนี้เราจะทำการ cache ข้อมูลเก็บไว้ที่ฝั่งของ client / user เลย ทำให้เราไม่จำเป็นต้องไปเรียกใช้ข้อมูลผ่าน web server ของเรา เช่น ถ้าเราไปเรียกรูปภาพมา รู้ภาพนั้นจะถูก cache ไว้บน browser ทำให้เมื่อเราเรียกใช้งานมันอีกครั้ง มันจะดึงเรารูปนั้นมาแสดงได้ทันที
ทั้งหมดนี้เป็นตัวอย่างตำแหน่งต่างๆ ในระบบ ที่เราสามารถ cache ข้อมูลได้ โดยเราสามารถแบ่งข้อมูลออกเป็น 2 แบบ คือ ข้อมูลคงที่ กับ ข้อมูลที่เป็น dynamic
โดยที่เราจะพยายาม cache ข้อมูลที่เราเข้าถึงข้อมูลนั้นบ่อยๆ และไม่ค่อยมีการเปลี่ยนแปลงบ่อยมากนัก
HTTP Caching สำหรับ Static Data
เรามาลงรายละเอียดของการ cache ข้อมูลที่เป็น static data กันอีกหน่อย ซึ่งเราในบทความนี้เราจะเน้นไปที่ HTTP เป็นหลัก เนื่องจากข้อมูลส่วนใหญ่เราเรียกใช้ผ่าน HTTP Protocol กัน
เริ่มต้นที่ ตัวอย่างของระบบกันก่อนว่า ระหว่าง web browser กับ web service นั้น เราสามารถ cache อะไรได้บ้าง
สมมติว่าเรามี Web Application ที่เข้าถึงได้ผ่านทาง browser และส่ง request ไปที่ Web Service ของเรา ซึ่งโดยทั่วไปแล้ว ระหว่าง 2 ตัวนี้ มักมี Service กลางที่เป็นตัวคั่นไว้อยู่ นั่นคือ Proxy หรือ Reverse Proxy ซึ่งตรงนี้เราสามารถที่จะ cache ข้อมูลเก็บไว้ได้
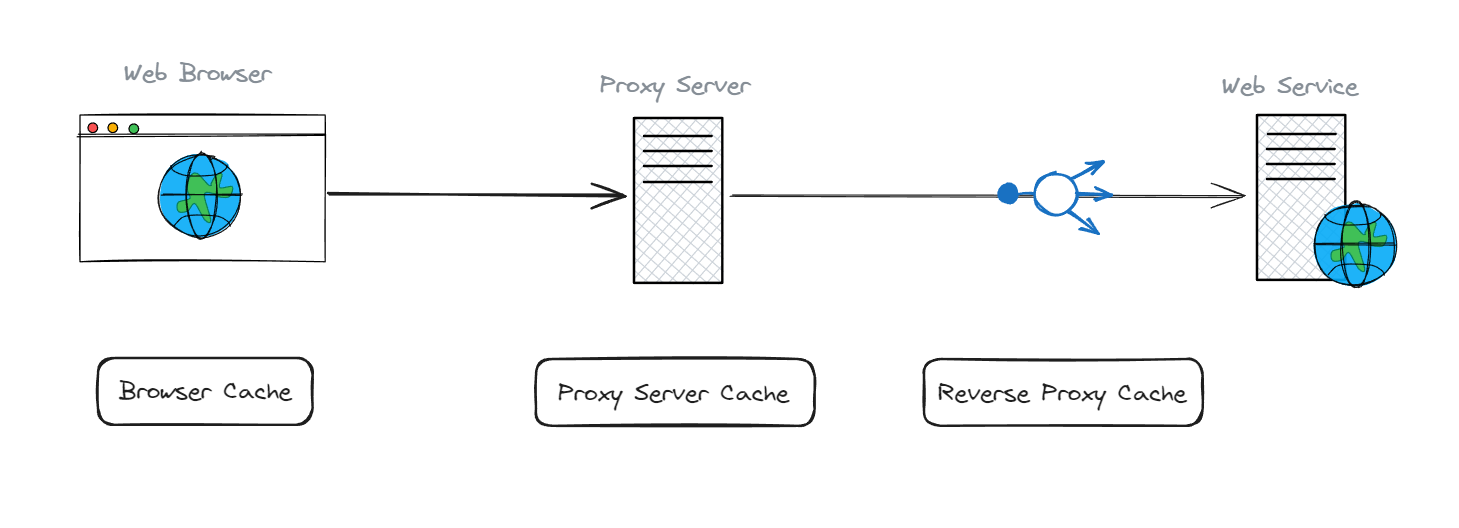
ทั้ง 2 ตัวนี้อยู่ใกล้ user มากที่สุด รองลงมาจาก browser หากเราเข้า web ผ่าน browser ตัวไหนก็ตาม โดยทั่วไปแล้ว ทุกๆ request และ response ทั้ง 2 ตัวนี้ก่อน ถึงจะไปที่ web services ซึ่งเราอาจจะมี web services ที่อาจมีหลายๆ instant
ถ้าอยากรู้ว่า 2 ตัวนี้ต่างกันยังไง กดลิ้งด้านล่าง...

ดังนั้นถ้าหากว่า เรามีข้อมูลที่เป็น static data ก็สามารถเอามา cache ไว้ที่ทั้ง 2 ตัวนี้ได้ ทำให้เราไม่จำเป็นต้องวิ่งไปขอข้อมูลจาก web services อีก
การ cache ในส่วนของ proxy server นั้น ผมจะเรียก cache ในส่วนนี้ว่า public cache ที่ทุกคนสามารถเข้ามาดึงข้อมูลไปใช้ได้
ซึ่งอาจจะต่างกับ browser และ reverse proxy ที่เป็น private cache ที่เป็นข้อมูลเฉพาะของใครของมัน
เมื่อเรารู้แล้วว่า ข้อมูลลักษณะไหนบ้าง ที่ควร cache ไว้ จะแบบ private หรือ แบบ public ก็ขึ้นอยู่กับลักษณะของข้อมูลเลย
ต่อไปผมจะวิธีการใช้งาน cache ผ่านทาง HTTP...
GET Method
ตัวแรกเริ่มต้นที่ GET Method กันก่อน มันเป็นตัวช่วยให้เราสามารถตัดสินใจได้ง่ายขึ้น ว่า อะไรควร cache
พูดง่ายๆ เลย คือ ถ้าหากมีการ call request ผ่าน HTTP โดยใช้ GET Method เราสามารถนำเอา request ของตัวนั้นมาพิจารณา ว่า ข้อมูลมีการเปลี่ยนแปลงบ่อยแค่ไหน และมีการขอบ่อยแค่ไหน
เราคงไม่เอาทุกๆ GET Request มาทำ cache เพราะบางอย่างมันไม่คุ้มค่าพอ โดยเฉพาะข้อมูลที่มีการเปลี่ยนแปลงบ่อยๆ หรือ ไม่ค่อยมีการเรียกใช้งาน
ถ้าหากใครมีการ call request ผ่าน POST Method เพื่อดึงข้อมูลมาแสดงผล ตัวนี้เราอาจจะต้องมาพิจารณาดูอีกทีว่า ข้อมูลที่ส่งกลับมานั้นควร cache หรือไม่ เช่น เดียวกับ GET Method
ส่วน Method อื่นๆ ที่เป็นเรื่องของการแก้ไข หรือ ลบข้อมูล พวกนี้เราไม่ cache กันอยู่แล้ว
Headers
เราสามารถกำหนดได้ว่าข้อมูลไหนควร cache โดยทำผ่าน cache-control ใน header โดยมันจะระบุอยู่ 2 สิ่ง คือ
- ข้อมูลนี้ควรถูก cache หรือไม่
- ถ้าหากควร cache แล้วควรใช้ระยะเวลาเท่าไรในการ cache
สำหรับตัว cache-control นั้น มีคำสั่งทั่วๆ ไปที่ควรรู้ไว้ ได้แก่
- no-cache: ต้องตรวจสอบกับเซิร์ฟเวอร์ก่อนใช้เวอร์ชันที่ cache ไว้
- no-store: ห้ามจัดเก็บข้อมูลใน cache
- max-age: กำหนดระยะเวลาที่ข้อมูลยังใช้ได้ใน cache
- public: อนุญาตให้ cache โดยทุกอุปกรณ์
- private: อนุญาตให้ cache เฉพาะบนเบราว์เซอร์ของผู้ใช้
โดยเราสามารถเข้าไปดูรายละเอียดเพิ่มเติมได้ที่นี่


ETag
แท็กสำคัญอีกหนึ่งตัว คือ ETag เจ้าตัว ETag ตัวจัดการเวอร์ชันของข้อมูลประเภทหนึ่ง ซึ่งหลักการทำงานของมัน ผมได้เขียนแยกไปอีกหนึ่งบทความแล้ว
สมมติว่า เรามีรูปภาพ บน web services ของเรา (เป็น resource อย่างอื่นก็ได้นะ) เราสามารถติดป้ายกำกับรูปภาพนั้น ผ่านการใช้ ETag ของเรา เพื่อทำการ cache รูปภาพนั้นไว้
โดยเราจะ cache รูปภาพนี้ไว้บน browser หรือ proxy server ก็ได้ แล้วแต่เราเลย (ถ้าเป็นรูปภาพ แนะนำให้ cache ไว้บน browser)
เมื่อไหร่ก็ตามที่มีการเรียกรูปภาพผ่านทาง url เดิม และ ETag เดิม ตัวระบบก็จะไปเช็คว่า ETag ของเรามีอยู่หรือเปล่า หรือ มีการเปลี่ยน ETag เป็น version ใหม่แล้ว
ถ้าหาก ETag ไม่ตรงกัน ก็จะไปดึงรูปภาพนั้นมาใหม่ และเอา ETag version ใหม่มาแทน และทำ cache ใหม่อีกครั้งหนึ่ง
ดังนั้น ถ้าหากว่า ตัว ETag ไม่มีการเปลี่ยนแปลง ระบบก็ไม่จำเป็นต้องวิ่งไป Query หรือ ดึงข้อมูลจาก web services อีก จนกว่าข้อมูลนั้นจะเปลี่ยนแปลง ข้อมูลบางอย่างอาจจะอยู่บน browser ของ user เป็นปีๆ เลยก็ได้
นี่คือการทำงานของ ETag แบบคร่าวๆ ให้พอนำไปประยุกต์ใช้งานกัน และนี่คือวิธีการทำงานของ HTTP Caching
Caching สำหรับ Dynamic Data
โดยทั่วไปแล้ว dynamic data นั่น เราจะใช้เรียกข้อมูลที่มีโอกาศ หรือ ความเป็นไปได้ที่ข้อมูลนั้นจะเปลี่ยนแปลงอยู่เสมอ ซึ่งจะไม่เหมือนกับพวกไฟล์ Javascript, CSS, Image ที่จะไม่ค่อยมีการเปลี่ยนแปลง นอกจากเราจะเอา version ใหม่ขึ้นไปเท่านั้น
สำหรับการ cache ข้อมูลที่เป็น dynamic นั้น โดยพื้นฐานแล้วจะมี 2 วิธีในการ cache ข้อมูลที่เป็น dynamic คือ
- Exclusive Cache (ใช้แคชเฉพาะบุคคล)
- Shared Cache (ใช้แคชร่วมกัน)
ก่อนที่เราจะลงรายละเอียดแต่ละตัว ขอทำความเข้าใจเกี่ยวกับการ caching ข้อมูลกันก่อน ว่า ข้อมูลแบบไหนบ้างที่เราหยิบเอามาทำการ cache
โดยทั่วไปแล้วข้อมูลที่เราจะเอามาพิจารณาเพื่อทำ cache เก็บไว้นั้น เราจะดูที่ 2 เรื่องหลักๆ นั่นคือ
- ข้อมูลมีการเรียกใช้งานหรือมีการเข้าถึงบ่อยแค่ไหน?
- ข้อมูลมีการเปลี่ยนแปลงบ่อยแค่ไหน?
ดังนั้น เพื่อให้เราสามารถเลือกใช้งาน cache บน service ได้อย่างมีประสิทธิภาพ จำเป็นต้องมี 1 ใน 2 ข้อนี้เสมอ
อีกอย่างหนึ่งก็คือ...
เราจะ cache มันไว้ที่ไหน ระหว่าง Web Services กับ Services / APIs Services ซึ่งเราจะต้องมาพิจารณาตรงนี้ด้วยว่า ข้อมูลไหน ควร cache ไว้ที่ไหน Web Services หรือ Services ทั่ง 2 ตัวนี้เหมาะแก่การ cache ข้อมูลที่เป็น dynamic
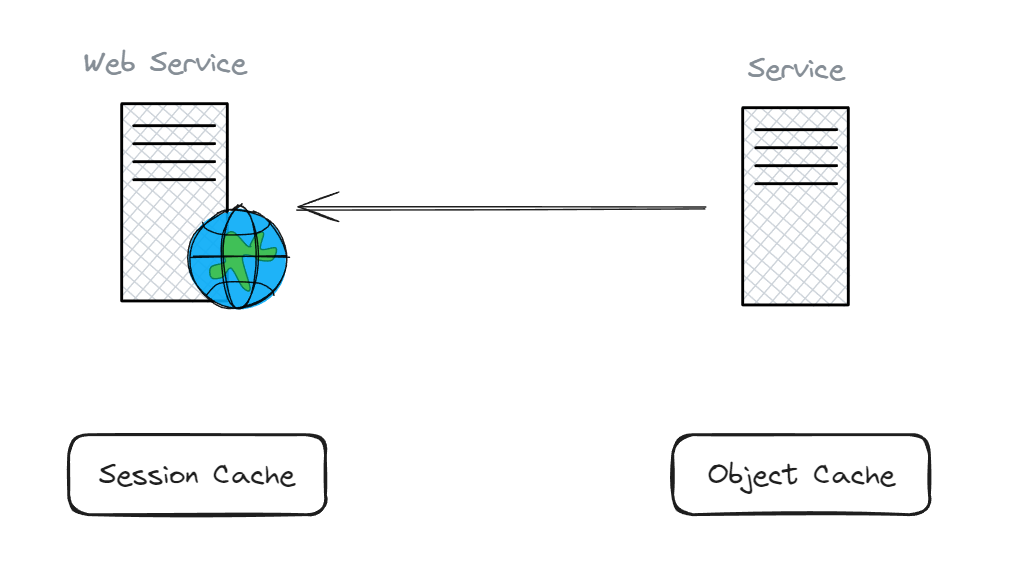
เช่น...
สมมติว่า Web Services ของเรา ได้รับข้อมูล โปรไฟล์ของผู้ใช้ มาจาก request ไปขอข้อมูลจาก Service (APIs Service) ที่ไปดึงข้อมูลมาจาก database อีกทีนึง และเป็นไปได้ว่า user จะมีการขอข้อมูลนี้อีก หลังจากผ่านไป 2 นาที (หรือถ้าใครเป็นสาย front-end พวก React ก็จะพอเห็นว่า บางครั้งถ้าหากเขียนโค๊ดไม่ดี อาจมีการเรียก APIs เส้นเดิมมากกกว่า 1 ครั้งได้) ซึ่งการเรียกใช้ข้อมูลเดิม มันทำให้เราเสีย bandwidth และ process ที่ไม่จำเป็น
ดังนั้น หากข้อมูลนั้นถูกแคชไว้ภายใน Web Service แล้ว ก็จะช่วยปรับปรุงประสิทธิภาพได้ดีขึ้นมาอีกระดับหนึ่ง แทนที่จะไปดู cache จาก APIs Service ให้เปลือง bandwidth และ Latency เล่น
ปูพื้นกันมาพอสมควร... เรากลับมาที่เรื่องหลักของเรากันดีกว่า...
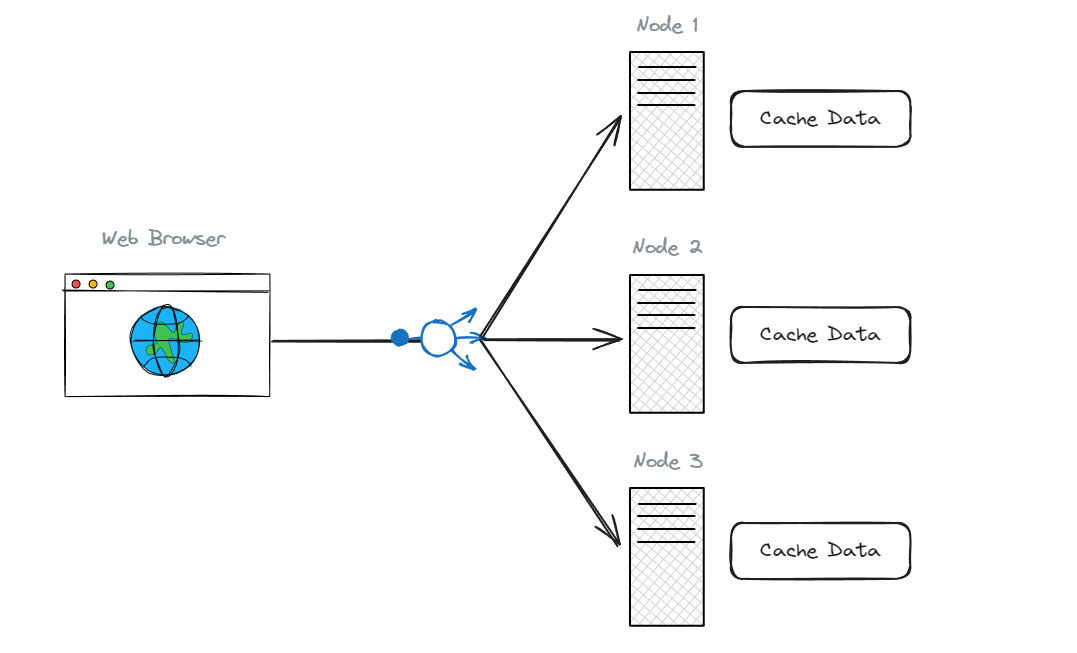
Exclusive Cache
มันเป็นการ cache ข้อมูลไว้ในแต่ละ node หรือพูดง่ายๆ ว่า แต่ละ node จะเก็บ cache เป็นของตัวเอง
ตัวอย่างเช่น...
สมมติว่าเรามี web service และมีการไปดึงข้อมูลบางอย่างจาก Services / APIs services ตัว web service สามารถ cache ข้อมูลนั้นไว้ในหน่วยความจำของตัวเองได้
ดังนั้น cache นี้ จึงอยู่ภายใน instance ตัวนั้น ในครั้งต่อไปหาก instance นั้น ต้องการข้อมูลก็จะสามารถไปดึงข้อมูลจาก cache ได้เลย แทนที่จะไปขอข้อมูลจาก services มันเลยทำให้ช่วยลด latency ให้ต่ำลงไปได้
ทีนี้ลองนึกภาพดูว่า ถ้าหากเรามี instance หลายๆ ตัว ข้อมูลก็จะถูก cache ไว้ในแต่ละ instances เลย
ถ้าหากเราไม่ได้ route ให้มันไปที่ instance เดิมทุกครั้ง มันก็จะทำการสร้าง cache ของข้อมูลนั้นใหม่บน instance นั้น
ทำให้เกิดการซ้ำซ้อนกันของข้อมูลได้ เพราะยังไม่มีข้อมูลนั้นๆ ซึ่งปัญหานี้มันสามารถจัดการได้ด้วยการกำหนดให้ route ไปหา node เดิม แต่มันก็ดูยุ่งยากกว่าการใช้ cache อีกแบบหนึ่ง (เลยไม่ขอลงรายละเอียดละกัน)
ดังนั้น exclusive cache จะเหมาะกับตัวข้อมูล (dataset) ที่มีขนาดเล็ก และ ถ้าหากเราใช้งาน node หลายๆ ตัว มี load balancing ก็ให้ใช้ session cache จะเหมาะสมที่สุด
Shared Cache
จากข้อเสียของ exclusive cache เราสามารถปิดได้โดยการใช้ shared cache โดยการแยกเอาข้อมูลที่ต้องการ cache ไปเก็บไว้ที่ node กลาง (หรือ cache data)
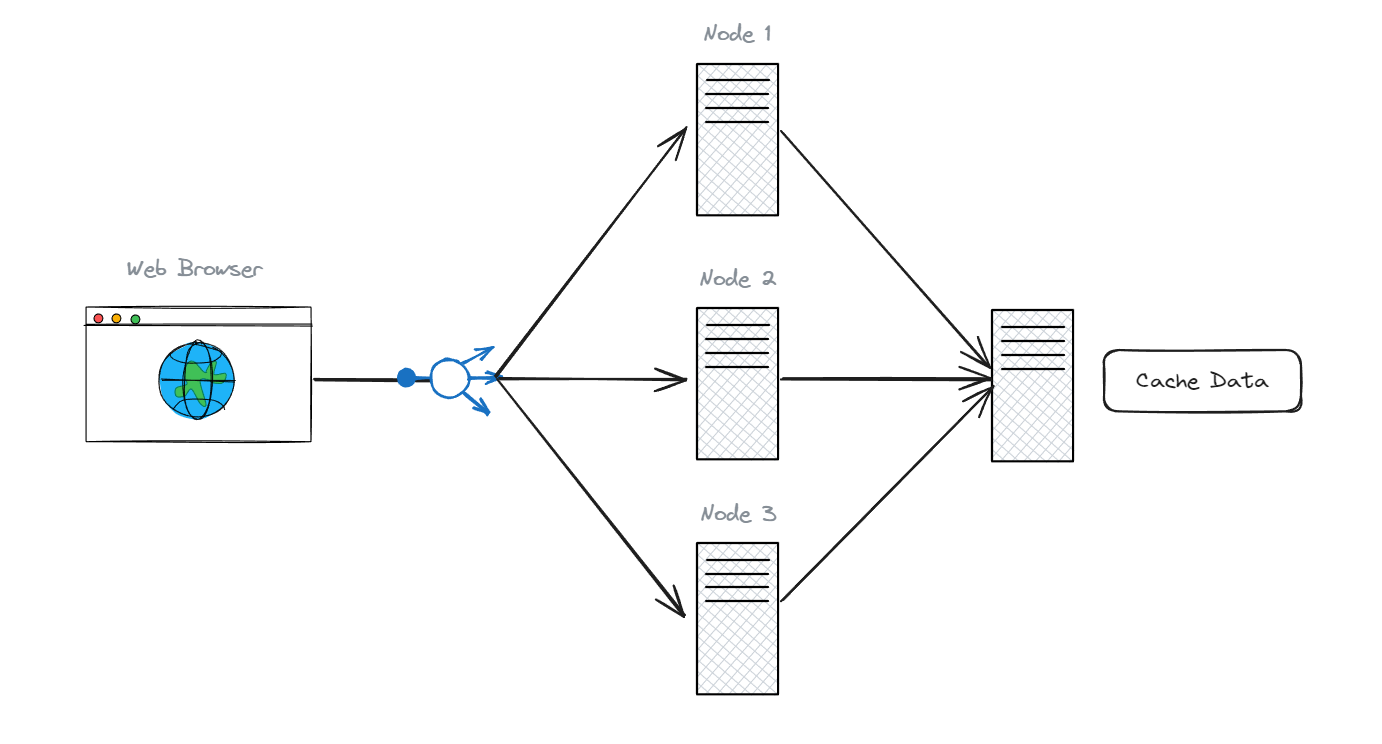
แต่วิธีนี้จะทำให้ latency เราเพิ่มขึ้นมาอีกหน่อย เนื่องจากต้องมีการเพิ่ม Hub ใหม่ เข้าไปใน Network ซึ่งเป็นการกระโดดออกไปอีก services นึง
แน่นอนว่า มันเพิ่ม cost และ latency เข้ามาอีกหน่อย ต่อให้เป็นแค่หลัก millisecond ก็ตาม แต่มันช่วยให้เราจัดการ cache ได้ง่ายกว่า
ซึ่งวิธีนี้ มีข้อดี คือ ทุก node สามารถใช้ cache ร่วมกันได้ ลดความซ้ำซ้อนของข้อมูล และสามารถ scale out cache ออกไปได้ง่ายกว่า
โดยส่วนใหญ่แล้ว เมื่อข้อมูลที่ cache มีขนาดใหญ่ขึ้น และ มีการใช้งานร่วมกันแบบนี้ เราจำเป็นต้องมีตัวจัดการ cache ที่รู้จักกัน เช่น Memcache, Redis เป็นต้น
เท่านี้คิดว่าพอจะเห็นภาพของ 2 วิธีการในการทำ dynamic cache แล้ว
Challenges of Caching
ในการใช้งาน cache นั้น มีความท้าทายอยู่ 2 เรื่องใหญ่ๆ ด้วยกัน คือ
- ขนาดของ cache ที่จำกัด
- ความถูกต้องของข้อมูล
ก่อนที่จะไปพูดถึง 2 ข้อนี้ขอ แวะสักนิด
Cache Hit Ratio
เราจะรู้ได้ไงว่าการใช้ cache ของเรามีประสิทธิภาพแล้วหรือยัง? เราสามารถใช้ตัว cache hit ratio มาเป็นตัววัดได้ โดยใช้สูตรนี้
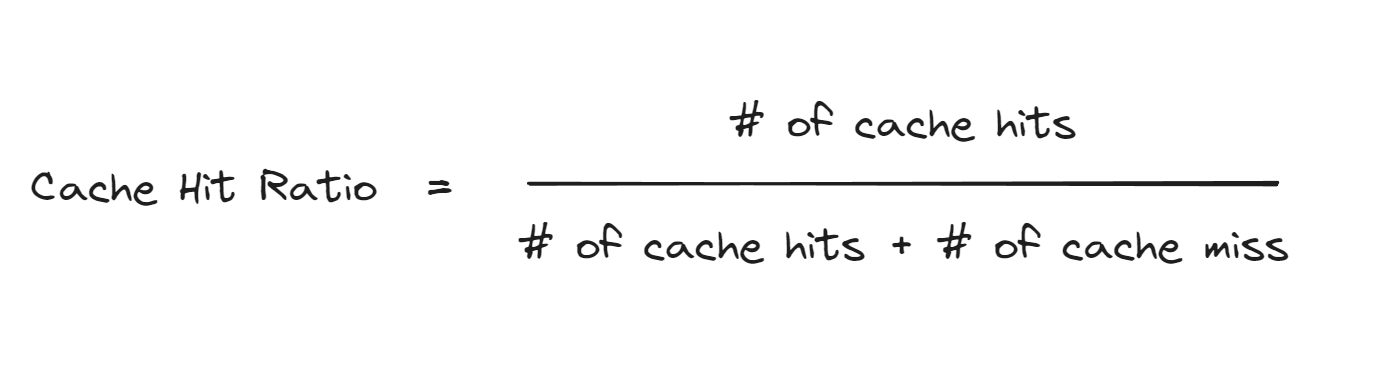
- # of cache hits: จำนวนของ request ทั้งหมด ที่เข้าไปใช้งาน cache
- # of cache miss: จำนวนของ request ทั้งหมด ที่ไม่ได้เข้าไปใช้งาน cache
โดยทั่วไปแล้ว หากเราถามว่าค่าที่เหมาะสมของ cache hit ratio เป็นเท่าไหร่ ขอตอบเลยว่า ขึ้นอยู่กับหลายปัจจัย เช่น
- ประเภทของ Applications / Services
- รูปแบบการเข้าถึงข้อมูล
- ขนาดของ cache
- อัลกอริทึมที่ใช้ในการ cache
บางอย่างเราสามารถใช้ cache ได้เยอะ cache hit ratio ก็สามารถกำหนดให้สูงๆ ได้ แต่บางอย่างอาจจะทำ cache ได้น้อย ก็ทำให้ cache hit ratio ได้น้อยตาม
ดังนั้น มันขึ้นอยู่กับปัจจัยต่างๆ ของแต่ละ applications / services เลย แต่ถ้าอยากได้แนวทางไว้เป็นตัวตั้งต้น ก็จะวางไว้ให้ดังนี้:
- 80-90% ขึ้นไป: ถือว่าดีมาก แสดงว่าระบบแคชทำงานได้อย่างมีประสิทธิภาพสูง
- 60-80%: ค่อนข้างดี แต่อาจมีพื้นที่ให้ปรับปรุง
- ต่ำกว่า 60%: อาจต้องพิจารณาปรับแต่งระบบ cache
กลับไปที่ความท้าทายของการใช้งาน cache กัน...
Limited cache space results early evictions
ความท้าทายแรกเลย คือ ความที่ขนาดพื้นที่ของ cache นั้นมีจำกัด อย่างที่เรารู้ การ cache นั้น เป็นการเอาข้อมูลไปเก็บไว้ใน memory ซึ่งเร็วกว่าการไปดึงข้อมูลจาก disk
แต่ memory มันก็เป็น resources ที่ราคาแพงกว่า disk ด้วย การเพิ่ม memory ให้มีขนาดความจุเยอะๆ มันก็เป็นการเพิ่ม cost ในส่วนนี้เข้าไปด้วยเช่นกัน ดังนั้น memory ของเราจึงมีจำกัด เพื่อให้ cost ยังอยู่ในช่วงที่รับได้ ยังคุ้มค่าอยู่
สมมติว่าเรามี memory size ที่จำกัด มันอาจจะทำให้บางครั้งข้อมูล ที่เรา cache ไว้ อาจจะถูกลบออกไปก่อนกำหนดได้ และเมื่อมันถูกลบออกก่อนกำหนด เมื่อต้องการข้อมูลนั้น แทนที่เราจะไปดึงมาจาก cache ก็จะต้องไปขอข้อมูลจาก services และทำการ cache มันใหม่ อีกครั้งหนึ่งแทน
ดังนั้นจึงทำให้ เราจะต้องตัดสินใจว่า จะ cache ข้อมูลอะไรบ้าง และข้อมูลไหนที่จะไม่ cache โดยทั่วไปแล้วข้อมูลที่เราจะ cache จะมีคุณสมบัติหลักๆ อยู่ 3 อย่าง คือ
- ข้อมูลเป็นแบบอ่านอย่างเดียว
- ข้อมูลนั้นถูกเข้าถึงบ่อยๆ
- ขนาดของข้อมูล (cache object)
ข้อมูลนั้นถูกเข้าถึงบ่อยๆ เช่น ข้อมูลที่มีการขอทุกชั่วโมง หรือ หลักนาที อันนี้สามารถ cache แต่ถ้านานๆ เข้ามาขอที เช่น วันละครั้งหรือนานๆ ครั้ง ก็ไม่จำเป็นต้อง cache
ขนาดของข้อมูล อันนี้แน่นอนว่า ถ้าเราเอาข้อมูลที่มีขนาดใหญ่เข้าไป cache มันก็กินพื้นที่ ดังนั้นพยายามลดขนาดให้มันเล็กลง หรือ ไม่ใหญ่จนเกินไป
นี่คือ ความท้าทายหนึ่งที่เราจะได้เจอ หากเรามีพื้นที่ของ memory ที่จำกัน แต่ถ้าเรามีพื้นที่ของ memory เยอะ ความท้าทายในเรื่องนี้ก็ไม่ค่อยส่งผลอะไรมากนัก (แต่เราก็ cache ทุกอย่างไม่ได้อยู่ดี)
Cache invalidation & cache inconsistency
อีกหนึ่งความท้าทายในการใช้งาน cache นั้น คือ ข้อมูลใน cache มันเก่าไปแล้ว ไม่ตรงกับใน database ทำให้ข้อมูลไม่มีความสม่ำเสมอ (consistency) ข้อมูลไม่สอดคล้องกัน
มี 2 วิธีที่เราจะใช้ในการจัดการกับปัญหาเรื่องข้อมูลเก่า คือ
update or delete when source change: ให้ update หรือ delete ข้อมูลที่ cache ไว้ เมื่อมีการอัพเดทค่าจาก source อาจจะใช้วิธีอัพเดทข้อมูลใน cache หรือจะลบข้อมูลนั้น ใน cache ทิ้ง แล้วค่อย cache ขึ้นมาใหม่ เมื่อมีการ request เข้ามา วิธีนี้จะช่วงลดความไม่สอดคล้องกันของข้อมูลลงให้เหลือน้อยที่สุด (ขึ้นอยู่กับว่าใช้เวลาในการอัพเดทเท่าไหร่)
วิธีนี้เราจะทำได้ เมื่อ cache นั้น อยู่ภายใต้ระบบที่เป็นของเราเอง ถ้าเกิดว่า cache นั้นเป็น public cache เช่น HTTP หรือ Browser วิธีนี้เราก็จะไม่สามารถไปบังคับให้ update หรือ delete ข้อมูลนั้น ออกจาก cache ได้
Time-To-Live: การกำหนดค่า TTL ให้ข้อมูลที่ถูก cache วิธีนี้เราจะนำมาใช้กับ HTTP Caching หรือเอามาประยุคใช้กับ Browser Cache ก็ได้เช่นกัน โดยเราจะกำหนดเวลาสูงสุดที่จะเก็บข้อมูลนั้นไว้ใน cache
วิธีนี้ข้อดี คือ เราสามารถจัดการข้อมูลที่อยู่ใน public cache ได้
แต่มีข้อจำกัด คือ เราจะต้อง หาค่า TTL เหมาะสมของแต่ละข้อมูล
เพราะถ้าหากเรากำหนดอายุของ cache ไว้สูงเกินไป ข้อมูลก็จะไม่สอดคล้องกัน (inconsistency) กับ source แต่ถ้ากำหนดอายุต่ำเกินไป ก็ทำให้การเข้าไปใช้งาน cache ของเราก็จะลดลง (cache hits go down) แล้วไปดึงข้อมูลจาก source แทน ตรงนี้ใช้ cache ไม่ก็อาจจะไม่เห็นผล
นี่คือ ความท้าทายใหญ่ๆ ที่เราจะต้องเจอเมื่อเรา คิดที่จะใช้งาน cache
และ
ขอจบเรื่องของการใช้งาน cache ไว้เท่านี้