
การทำระบบที่ดีและสามารถรองรับการใช้งานได้นั้นเป็นสิ่งที่สำคัญเป็นอย่างมาก เพราะฉนั้นแต่ละครั้งที่เราออกแบบ Architecture นั้น เราจำเป็นต้องคิดถึงเรื่องนี้ด้วยเสมอ
ถ้าเราพูดถึงปัญหาของ performance ที่เกิดขึ้นมัน คือ ทุกๆ ปัญหาเรื่อง performance มักเกิดจาก ผลลัพธ์ที่เกิดขึ้นจากการรอคิวการประมวลผล จากที่ใดที่หนึ่งเสมอ เช่น Network socket queue, Database IO queue, OS run queue เป็นต้น
หากพูดถึงการรอคิวนั้น ให้เรานึกภาพการจราจรและรถยนต์ก็ได้ ซึ่งรถยนต์หนึ่งคันจะเปรียบเสมอ 1 request เมื่อไหร่ก็ตามที่มีปริมาณการรถที่เยอะบนถนนที่ใหญ่ รถก็ยังคงวิ่งได้สบายโดยที่ไม่ติดขัด แต่เมื่อไหร่ก็ตามถ้าถนนนั้นถูกแบบให้เล็กลง หรือเจอบางจุดที่เป็น bottleneck (คอขวด) ปริมาณรถที่วิ่งมาอย่างเยอะในตอนต้น จะเริ่มถูก block และบีบให้ได้ช้าลง

โดยเหตุผลหลักๆ ที่ทำให้เกิดการสร้างคิวขึ้น คือ
- การประมวลผลช้า หรือไม่มีประสิทธิภาพมากพอ
- การเข้าถึง resource แบบ serial (อนุกรม)
- ความจุของ resource ที่จำกัด
ถ้าเวลาเจอปัญหาเหล่านี้เรามักจะเอาคิวเข้ามาแทรก เพื่อเป็นการจัดการการใช้ resource ให้เหมาะสม ซึ่งก็เป็นเรื่องปกติที่เราจะทำกันอยู่แล้ว แต่ถ้าเมื่อไหร่ก็ตามเกิดการรอคิวที่นานขึ้นเมื่อไหร่ ก็เตรียมรับมือกับปัญหาเรื่อง performance ได้เลย
หากเราต้องการที่จะวัดเกี่ยวกับ performance ของระบบนั้น ว่าระบบที่ออกแบบมานั้นยังสามารถตอบสนองได้ดีอยู่มั้ย เราจะดูกันที่ workload กับ hardware
Workload
เราจะดูที่การทำงานของระบบที่ออกแบบเป็นหลัก ว่าในการทำงานนั้น มีการเรียกใช้ข้อมูลกี่ครั้ง และแต่ละครั้งเป็นจำนวนเท่าไหร่ รวมถึงจำนวน request volume เพื่อให้ทราบถึงปริมาณของข้อมูลที่ต้องการ เพื่อให้ระบบสามารถรองรับได้อีกด้วย
Hardware
เป็นการดูที่อุปกรณ์ โดยจะแยกออกเป็นแต่ละประเภท เพื่อดูว่า hardware แต่ละตัวนั้นมี capacity อยู่ที่เท่าไหร่ เพื่อให้เราสามารถประเมินและ monitor ได้ว่าตอนนี้ capacity เพียงพอต่อการใช้งานของระบบหรือไม่
System Performance Objectives
วัตถุประสงค์ในการวัดเรื่อง performance นั้น เราจะเน้นไปที่ 2 เรื่องหลักๆ คือ
- Minimize Request-Response Latency
เป็นการวัด เวลาที่ใช้ในการ processing (Latency) ในช่วงเวลาหนึ่ง ซึ่งมักจะขึ้นอยู่กับช่วงเวลาของการรอ (wait/idle time) และการ processing งานนั้นๆ มันจะทำให้เรารู้ว่าใน 1 request นั้นใช้เวลาเท่าไหร่ - Maximize Throughput
การวัดเพื่อให้รู้ว่าจำนวนงานที่รับได้มากที่สุดเป็นเท่าไหร่ โดยจะนับจำนวน request rate ที่รับเข้ามาประมวลผล ซึ่งจะขึ้นอยู่กับ Latency กับ Capacity ของระบบนั้นๆ เราจะรู้ได้ว่าระบบของเรานั้นรองรับการทำงานทั้งหมดในช่วงเวลาเดียวกันได้กี่ request
Performance Principles
หากจะดูเรื่อง performance นั้น เราจะดูกันที่ Efficiency (ประสิทธิภาพ), Concurrency (การจัดการหลาย ๆ งานในเวลาเดียวกัน) และ Capacity (ความจุ)
ก่อนจะไปลงรายละเอียดพวกนี้ เราต้องทำความเข้าใจเรื่องหนึ่งก่อน นั่นคือ การประมวลผลการทำงานแบบ Serial request, Concurrency requests
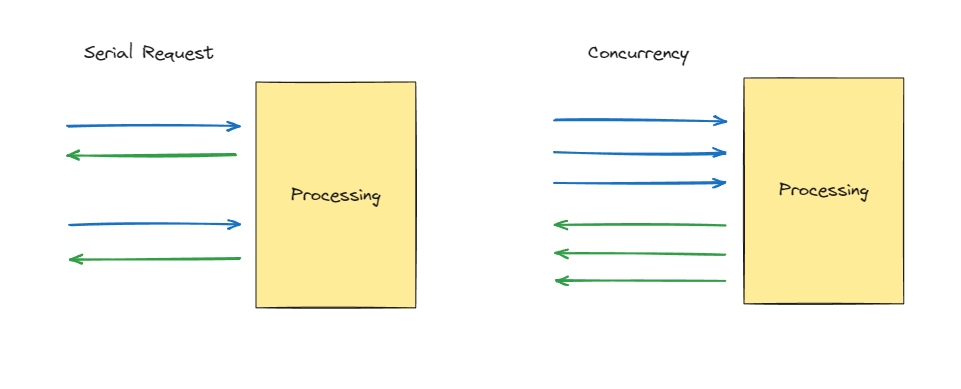
Serial request: เป็นการประมวลผลการทำงาน 1 request ให้จบก่อน แล้วจึงทำ request ใหม่มาทำ
Concurrency request: เป็นการประมวลผลหลาย ๆ งานในเวลาเดียวกัน
ดังนั้น
หากพูดถึงเรื่อง Efficiency นั้น เราจะดูกันที่การประมวลผลที่ 1 request แต่ถ้าหากเราพูดถึง Concurrency ก็จะเป็นการทำงานหลายๆ request พร้อมกัน
ส่วน capacity เป็นการพูดถึง resource ของระบบ เช่น CPU, Memory, Disk, Network เป็นต้น ซึ่ง 2 อย่างแรกจะ depend on มัน
กลับมาที่ 3 ตัวหลักของเรา
Efficiency
สิ่งที่ทำให้เกิด efficiency ให้แก่ request ของเรานั้นจะประกอบไปด้วย เรื่องพวกนี้ โดยจะดูว่า 1 request processing นั้นใช้งานเท่าไหร่
- Efficient Resource Utilization:
- IO - Memory, Network, Disk
- CPU
- Efficient Logic
- Algorithms
- DB Queries
- Efficient Data Storage
- Data Structures
- Database Schema (index, views, search etc.)
- Caching
Concurrency
เราจะดูว่าในหนึ่งช่วงเวลานั้น สามารถ execute ได้หลายๆ requests ซึ่งจำเป็นต้องพึ่งเรื่องของ Hardware และ Software เป็นหลัก
- Hardware
- Software
- Queuing
- Coherence
Capacity
เราจะดูว่า hardware แต่ละตัวนั้นมีความจุเท่าไหร่ รองรับได้แค่ไหน และถ้าหากจะเพิ่มต้องเพิ่มที่ตรงไหน
- CPU
- Memory
- Disk
- Network
ทั้งหมดนี้เป็นการจัดกลุ่มหลักๆ ในการดูเรื่อง performance โดยที่เวลาทำจริงจะมีรายละเอียดลงไปอีก