ผมที่ใช้ SQL และ NoSQL อยู่เป็นนิตย์ เกิดความสงสัยว่า Database นั้นมีอะไรบ้างที่ไม่ใช่สองตัวนี้ อีกตัวที่ใช้บ่อยๆ ก็คือ Key-Value อย่าง Redis แล้วยังมีอย่างอื่นอีกมั้ย เลยลองไปค้นหาและสรุปไว้คร่าวๆ ตามนี้
Relational Database Management System (RDBMS)
เปิดหัวด้วยตัวที่เราคุ้นเคยที่สุด คือ RDBMS ก่อนเลย ซึ่งตัวมันเองเป็นหนึ่งใน Database ที่นิยมใช้กันมากที่สุดตัวหนึ่ง โดยจะบริหารจัดการข้อมูลอยู่ในลักษณะของความสัมพันธ์ระหว่างข้องมูล (Relational) ซึ่งจะเก็บข้อมูลอยู่เป็นหมวดหมู่ในลักษณะของตาราง (Table) โดยแต่ละ table สามารถบรรยายความสัมพันธ์กับ table อื่นได้ และด้วยเหตุนี้มันเลยส่งผลให้เราสามารถ query ข้อมูลแบบซับซ้อนได้ นั้นคือการใช้งานพวก JOIN operation นั่นเอง
โดย RDBMS นั้นใช้หลัก ACID operations ได้แก่ atomicity, consistency, isolation, durability ซึ่งถือเป็นหนึ่งในข้อดีหลักของการเลือกใช้ RDBMS
โดยการการใช้งาน RDBM นั้น จะเป็นการจัดการข้อมูลเชิงโครงสร้าง จำเป็นจะต้องออกแบบโครงสร้างของ database ให้ดี เพราะมันจะการเก็บข้อมูลในรูปแบบของตารางตาม Data Model หรือ โครงสร้างของ table ที่วางไว้ทำให้การเก็บข้อมูลจะต้องมีความเป็นระเบียบเรียบร้อย และตัวมันเองยังทำหน้าในการยืนยันว่าข้อมูลที่เข้ามานั้นจะตรงตามที่วางไว้เสมอ (consistency) ดังนั้นมันค่อนข้าง strict พอสมควร
RDBMS ยังเหมาะกับการทำ transaction เพราะถ้าหากเรามี query ที่มี relation ต่อกันหลายๆ อัน การทำ transaction จะทำให้เรามั่นใจได้ว่าชุดของ query ภายใน transaction นี้ต้อง success ทั้งหมด ถ้ามีอันใดอันหนึ่ง fail ก็จะ fail พร้อมกันทั้งหมด (atomicity)
อีกอย่างแต่ละ transaction จะเป็นอิสระต่อกัน ถ้า transaction A มีข้อผิดพลาดบางอย่างเกิดขึ้นจะไม่ส่งผลต่อการทำ transaction B (Isolation) เพื่อป้องกัน business logic ที่ผิดพลาด นอกจากนี้เมื่อ transaction ถูก submit หรือ commit ไปแล้วจะถูกเก็บรักษาไว้อย่างดี เพื่อป้องกันเวลาระบบล่ม หรือไฟดับ จะมั่นใจได้ว่าข้อมูลทุกอย่างยังอยู่ตามเดิม (Durability)
ข้อดีของความเป็น Relational
- มีความเป็น ACID (Atomicity, Consistency, Isolation, and Durability)
- การที่มี Blueprint หรือ Schema ใน RDBMS นั้น ทำให้สามารถมั่นใจได้ว่าข้อมูลที่เข้ามาจะคงอยู่ใน format ตาม Schema ที่วางไว้ตลอด โดยที่ RDBMS จะจัดการเรื่องยุ่งยางอย่างการ Validation ให้ทั้งหมด
ข้อเสียของความเป็น Relational
- มี cost ในการปรับเปลี่ยนที่สูง ถ้าหากจะใช้ RDBMS จะต้องออกแบบฐานข้อมูลให้รัดกุม และ requirement ที่ค่อนข้างนิ่ง
- การทำ scaling นั้นทำได้ยากกว่า database รูปแบบอื่น แต่ช่วงหลังๆ ก็จะมี database บางตัวที่ที่ถูกออกแบบมาสำหรับการ scaling ได้แล้วเช่น CockroachDB หรือ PosgresSql
เมื่อไหร่ที่ควรใช้ Relational DB
- requirement ค่อนข้างชัดเจน หรือ มีการปรับเปลี่ยนโครงสร้างที่ไม่เยอะ ถ้าให้ดีก็แค่เพิ่มลด ปรับแก้ field ใน table
- ไม่ค่อยเหมาะกับข้อมูลที่เป็น unstructured
- การ JOIN ข้อมูลหลายสิบตารางพร้อมกันอาจไม่เหมาะกับการใช้งานแบบ real time ได้
Document Database

Document Database เป็นหนึ่งใน database ที่นิยมใช้มากที่สุดในยุคปัจจุบัน โดยภายใน database จะเก็บ document ที่เป็นเซ็ตของ key-value pairs หรือก็คือ JSON นั้นแหละ และ document เหล่านั้นจะถูกเก็บไว้ใน Collection (เปรียบเทียบคล้ายกับ Table ใน RDBMS) เพื่อทำให้ง่ายต่อการทำ Data Model

Document Database นั้นจะใช้คอนเซ็ปต์ของการทำ Denormalization ซึ่งตรงกันข้ามกับการทำ Normalization table ต่าง ๆ ใน RDBMS
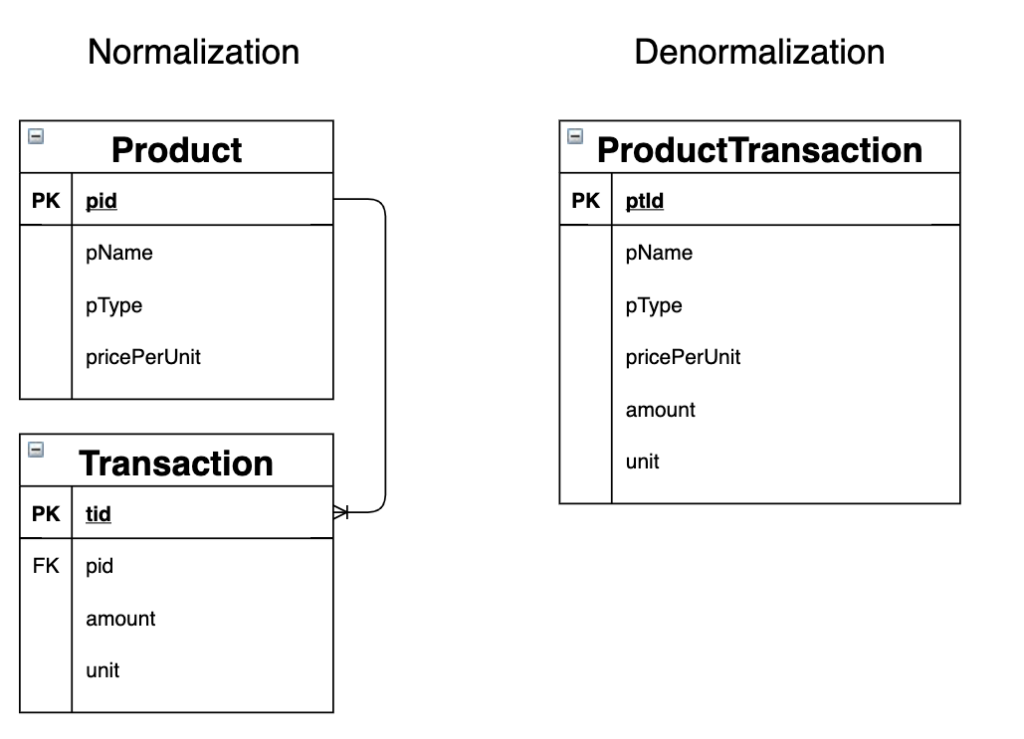
การทำ Denormalization จะคล้ายกับการรวมหลายข้อมูลจาก table มาแล้วให้เป็นหนึ่งเดียว ทำให้การ read ข้อมูลนั้นทำได้ไวมาก เมื่อเทียบกับ RDBMS ที่ต้องทำการ JOIN หลาย table จำนวนมากพร้อมๆ กัน
นอกจากนั้นภายในแต่ละ collection นั้นไม่จำเป็นต้องมี Schema ที่ตายตัว (Schema-less) ทำให้มีความยืดหยุ่น และสามารถรองรับ Data ทุกประเภท หรือ Data Structure ที่ซับซ้อนได้ เช่น Embedded Document, Nested JSON
อีกทั้งยังมีการ query ข้อมูลที่คล้ายกับ RDBMS (เพียงแต่ JOIN ไม่ได้) แต่ความที่มันเป็น Schema-less นั้นมันก็ทำให้มี Trade-off ในเรื่องของ ความซ้ำซ้อน (redundancy) และความไม่สอดคล้องกัน (inconsistency) ของข้อมูล ส่งผลให้การ write หรือ update ข้อมูลนั้นซับซ้อนยิ่งขึ้นเพราะไม่มีตัว validate schema เหมือน RDBMS
ข้อดี
- มีความยืดหยุ่นรองรับ Unstructured Data ได้ดี
- สามารถทำ horizontal scaling ได้โดยง่าย
- ใช้งาน query ง่าย ๆ ได้ และ read ข้อมูลได้เร็ว
ข้อเสีย
- ไม่สามารถ query ซับซ้อนได้เช่นการ JOIN
- Trade-off ของกับความที่เป็น ACID operation เพราะการที่เป็น schema-less, และ Denormalization เช่น inconsistency, การทำ transaction, ความยุ่งยากในการ update ข้อมูล
เมื่อไหร่ที่ควรใช้
- มี Unstructured Data เข้ามาเกี่ยวข้อง schema ของ data ยังไม่แน่นอน มี Nested Structured ที่ไม่ตายตัว
- มีเรื่องของ Scaling เข้ามาเกี่ยวข้องทั้ง Horizontal และ Vertical เช่น หากมีการเปลี่ยนแปลงของ requirement ตลอดเวลา หรือมีข้อมูลมีมหาศาลมากจนต้องเก็บอยู่ในหลาย Database Server
- ต้องการความเร็วในการ read ข้อมูล และไม่ควรมี query ที่ซับซ้อนมากนัก
- ยอมรับข้อเสียของการที่ไม่มี ACID operation ได้
Key-Value Database

การเก็บข้อมูลจะอยู่ในลักษณะ key กับ value โดยที่แต่ละ key นั้นจะไม่ซ้ำกัน และใช้ในการเป็น index สำหรับการเข้าถึง value เพราะฉะนั้นลักษณะของ Database ประเภทนี้จะเปรียบเสมือน Python dictionary หรือ JSON Object ขนาดใหญ่ที่สามารถเข้าถึง value ต่าง ๆ ได้ด้วยการ indexing ผ่าน key
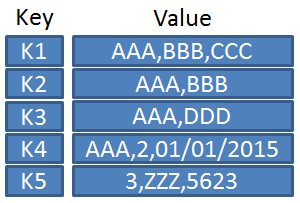
นอกจากนี้พวก Key-value Database อย่าง Redis นั้น เป็น in-memory data structure store ที่ถูกนำมาใช้เป็น Key-value Database ซึ่งมันจะเก็บ data ไว้ใน RAM หรือ Cache ของเครื่องเลย ทำให้ความเร็วในการทำ operations อย่าง read, write นั้นสูงกว่า Database ประเภทอื่นมาก (ความเร็วอยู่ในระดับ millisecond) อีกทั้งตัว value ยังรองรับ Data Type หลายประเภทอีกด้วย เช่น String, List, Set, Hash, Bitmap เป็นต้น
ด้วยความที่มันมีแค่ key กับ value ทำให้ไม่มีสามารถทำการ query, JOIN operations หรือมี Data Model ที่นอกเหนือจาก key-value ได้ ทำให้ไม่เหมาะกับ Complex Data อีกทั้งเนื่องจาก Data ถูก store อยู่ใน RAM ทำให้ไม่สามารถเก็บข้อมูลได้เยอะ เมื่อเทียบกับ disk storage ทั่วไป และข้อมูลจะหายไปเมื่อเครื่อง restart หรือดับไปเลย กู้คืนไม่ได้
ข้อดี
- ใช้งานง่าย มีแค่ get value กับ set value
- มี response time ที่สูงเนื่องจากใช้ RAM ที่มีความเร็วในการ access ข้อมูลสูง
- มีความยืดหยุ่นสูง รองรับ Data Type ได้หลากหลายเช่น List, String, Hash, Set ได้เป็นต้น
ข้อเสีย
- เก็บข้อมูลได้น้อยเนื่องจาก volume ของ RAM นั้นค่อนข้างต่ำเมื่อเทียบกับ storage รูปแบบอื่น
- short term memory
- ไม่เหมาะกับการ query ซับซ้อน ทำได้แค่ get value ตาม key
เมื่อไหร่ที่ควรใช้ Key-value Database
- หลักๆ ก็เหมาะกับการทำ Cache หรือ Session – โดยใช้ Key-value Database ในการลดเวลา response time ในการเข้าถึงข้อมูล นอกจากนั้นยังสามารถ store value ได้หลายประเภท เช่น โปรไฟล์ผู้ใช้ ข้อมูลประจำตัวผู้ใช้
- เน้นการเขียนข้อมูลแบบเรียลไทม์ เช่น การแสดงผล leaderboard ของเกมแบบ หรือ การสนทนาส่งข้อความแบบเรียลไทม์
Wide-column Database

Database ประเภทนี้จะคล้ายกับการนำ Key-value Database มาปรับแต่งในส่วนของ value โดยที่ value นั้นจะ store ในส่วนที่อยู่ในลักษณะ set ของ column แทนที่จะเป็น value เดี่ยว ๆ เหมือนใน Key-value Database
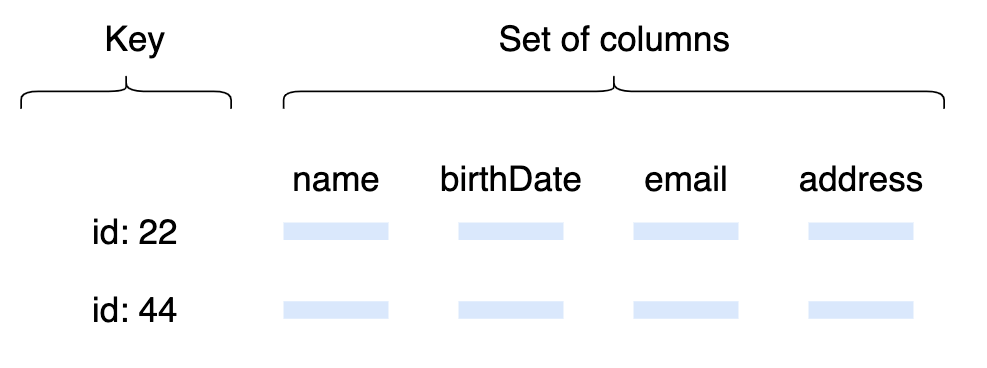
นอกจากนั้น Wide-column Database ก็ยังไม่มี Schema ที่ตายตัว (Schema-less) ทำให้สามารถจัดการกับ unstructured ได้ อีกทั้งยังมีระบบ fault tolerant ในตัว จากการที่เก็บข้อมูลไว้หลาย Data Node เช่น Apache H-Base ที่ operate อยู่บน Hadoop file system จะมีการเก็บข้อมูลเดียวกันไว้ 3 Data Nodes เพื่อที่ว่าหากมี Data Node อันใดอันหนึ่งเสียไป จะสามารถ recover ข้อมูลกลับมาได้
มีภาษาที่ใช้ในการ query ข้อมูลที่คล้าย SQL แต่ไม่ทรงพลังเท่า (เพราะว่า perform JOIN operation ไม่ได้) อย่าง CQL (สำหรับ Cassandra) รวมถึงยังไม่สามารถ index value นอกเหนือจาก key ของมันได้
อีกอ Wide-column Database นั้นจะสามารถ scale horizontally หรือสามารถทำ write operation ที่มีปริมาณมาก ๆ ได้ แต่ก็ยังไม่เหมาะสำหรับการใช้เป็น General-purpose Database อยู่ดีแต่อาจเหมาะกับการเป็น Data Lake ที่ต้องการความสามารถในการ dump data ที่หลากหลายเข้ามาตลอดเวลา (High Write, Large variety)
ข้อดี
- สามารถจัดการกับ Unstructured Data ได้
- สามารถทำ horizontal scaling ได้ง่าย
- รองรับการ write ในระดับข้อมูลขนาดใหญ่ได้ดี
- รองรับ fault tolerant ในการเก็บข้อมูล เช่นเวลามี Data Node พัง
ข้อเสีย
- ไม่สามารถทำ query ที่ซับซ้อนได้อย่าง JOIN ใน SQL
เมื่อไหร่ที่ควรใช้ Wide-column Database
- High write – มีการ write ข้อมูลบ่อย ๆ และจำนวนมาก ๆ เช่นข้อมูลที่เป็น time-series หรือเป็นสตรีมของข้อมูลจากหลาย IoT devices ทุกวินาที, ข้อมูลตลาดหุ้น
- Low read – ไม่จำเป็นต้องมีการอ่านข้อมูลแบบ real time หรือไม่จำเป็นต้องมี complex query พวก JOIN operation
- Large variety of Data – มี Data ข้อมูลไหลเข้ามาหลายประเภทเช่น unstructured, structured, semi-structured
Graph Database

ภายใน Database นั้นจะเก็บอยู่ในลักษณะของ Node และ Edge โดยข้อมูลจะถูก store อยู่ใน Node และมีการ define relationship ของแต่ละ Node ผ่าน Edges
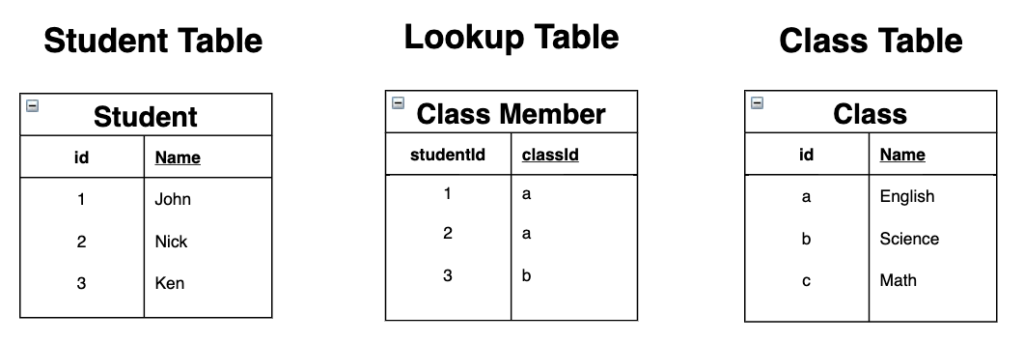
การจะหาว่ามีนักเรียนคนใดบ้างที่ลงคอร์สเรียน English ไปบ้างนั้น จำเป็นต้องมี Lookup/Middleman Table ทีเก็บข้อมูลว่านักเรียนคนไหนลงคอร์สใดไปบ้าง (การทำ Normalization ใน RDBMS) และจำเป็นต้องการใช้ JOIN ระหว่าง Table ดังภาพด้านบน
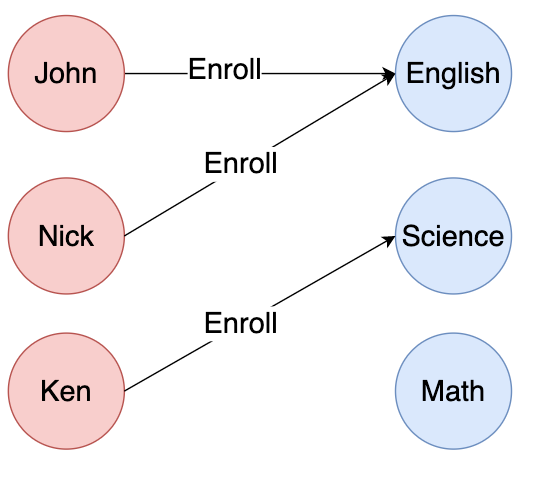
แต่ถ้าหากเป็น Graph Database นั้นมันจะ define relationship ลักษณะนี้ได้โดยไม่ต้องมี Table ที่ต้องมาเก็บ relationship ระหว่าง Data แต่หลักการของ Graph Database จะสามารถ define relationship ได้ที่ Edge โดยตรงดังภาพด้านบน
ให้การเก็บข้อมูลในลักษณะนี้ บรรยายความสัมพันธ์ระหว่าง Entity ได้โดยง่าย และตรงไปตรงมา นอกจากนั้นยังหลีกเลี่ยง complex query อย่างการ JOIN หลายตารางมาก ๆ ที่เป็นปัญหาหนึ่งใน RDBMS
ข้อดี
- Query speed สูงมากในกรณีที่ต้องการหา relationship ระหว่าง Node (ถ้าหากเป็น RDBMS นั้นจำเป็นต้อง JOIN หลายตาราง หรือมี Lookup Table)
- เป็นการเก็บข้อมูลที่อธิบาย relationship ของแต่ละ Node ได้ตรงไปตรงมา และ visualize ออกมาได้ง่าย
- มีความ flexible สูง ไม่จำเป็นต้องมี schema ที่ตายตัว
ข้อเสีย
- มีปัญหาเรื่องการทำ scaling
- ไม่เหมาะกับ High Write (มีการเขียนข้อมูล volume สูง ๆ)
- จำนวน vendors กับ userbase ยังต่ำอยู่ ทำให้ community ยังไม่โตเท่าที่ควร ส่งผลให้ยังไม่มี integrated tools, lib ต่าง ๆ หรือพวก data connector สำหรับใช้งานแต่ละ platform
เมื่อไหร่ที่ควรใช้ Graph Database
- ต้องการความเร็วในการ query data ที่มี relation ซับซ้อน (ต้องการ JOIN หลายตารางใน RDBMS) เช่นการทำ Realtime Recommendation System
- Data มี relationship ระหว่างกันมาก ๆ เช่นข้อมูลใน Wikipedia, Social Media Platform (อาจไม่เหมาะถ้าหากข้อมูลมีการ write เข้ามาใน volume ที่สูงมาก ๆ เช่น Facebook)
- ต้องการความง่ายในการ visualize relation ระหว่าง Data ที่มีอยู่
Search Database

จะมีลักษณะคล้าย Document Database แต่มีความต่างกันตรงที่ Document Database จะ assign index แล้วจึง insert document บน index นั้น ในขณะที่ Search Database จะทำตรงกันข้ามนั้นก็คือหลังจาก insert document เข้าไปแล้วตัว Search Database จะทำการ generate index ขึ้นมาให้จากคำสำคัญ หรือ term ต่าง ๆ (inverted index) เหมือนกับหน้า appendix ในหนังสือที่เราไว้ใช้ค้นหา Term หรือ Keyword สำคัญต่าง ๆ ว่าอยู่หน้าใดของหนังสือบ้าง
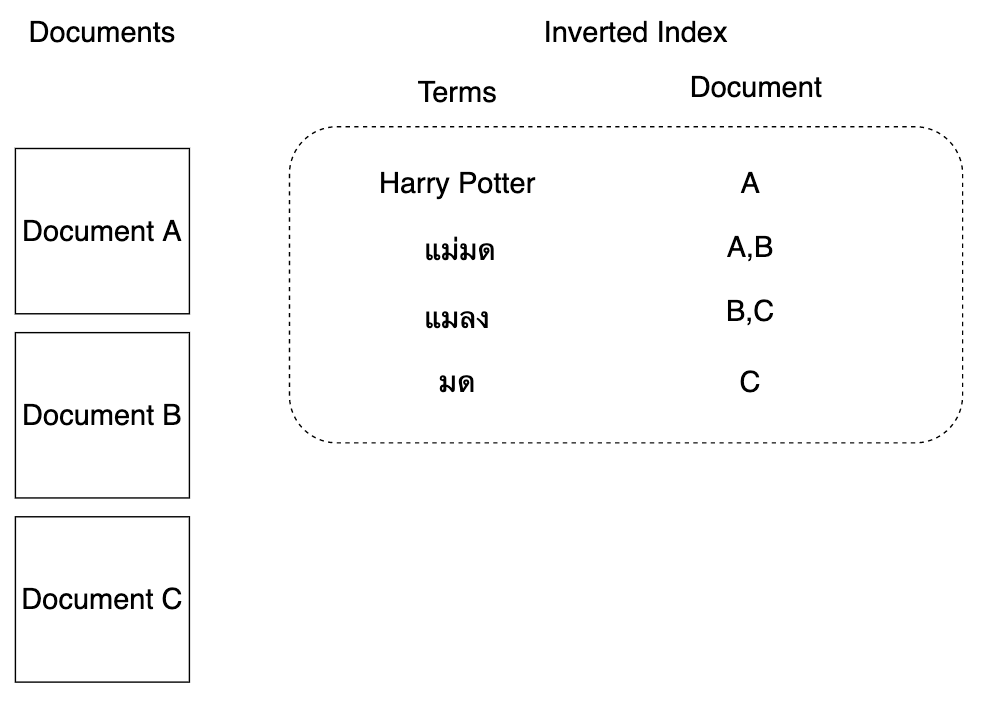
ข้อดี
- เร็วมาก ๆ ในการ query ที่เป็น Text Based (ตาม inverted index ของมัน แล้วแต่จะกำหนด)
- ไม่มี Schema เพราะเก็บเป็น Document Based (สำหรับ ElasticSearch จะรองรับข้อมูลที่เป็น JSON เท่านั้น)
- Scale ได้ง่าย
ข้อเสีย
- ไม่เหมาะกับการทำ Relational Query
- ต้องการ fine tuned พอสมควรถึงจะมี performance ที่ดี
เมื่อไหร่ที่ควรใช้
- การทำ Search Engine ภายใน Application, Enterprise ได้หมด
- Auto-suggestion, Auto-complete
- นำไปเสริม technology อื่นเช่นการทำ indexing ให้ Hadoop เพื่อทำให้ read ข้อมูลได้ไวขึ้น
ดังนั้นหลักการนี้จึงทำให้เหมาะกับการทำ Search Engine หรือพวก Type Ahead (Auto-suggestion ตอนพิมพ์คำ) มาก ๆ เนื่องจากเป็นการใช้ search text ที่มักจะเป็น Term ต่าง ๆ ที่ store อยู่ใน inverted index ทำให้มันเร็วมาก ๆ ในการค้นหา Document จาก search text นอกจากนั้นยังสามารถ custom algorithm ในการ search ได้ด้วย