ในการออกแบบระบบ ออกแบบเครือข่าย หรือ ออกแบบฐานข้อมูลนั้น มีหลายอย่างที่ต้องคำนึง เพื่อให้ระบบนั้นมีข้อผิดพลาดน้อยที่สุด และ เป็นไปตามวัตถุประสงค์ของระบบ
ฉะนั้นจึงต้องรู้จักกับ CAP theorem โดย CAP theorem ซึ่งมันเป็น แนวคิดพื้นฐานที่จะช่วยให้ทำความเข้าใจข้อดีข้อเสียเกี่ยวกับระบบที่มีอยู่
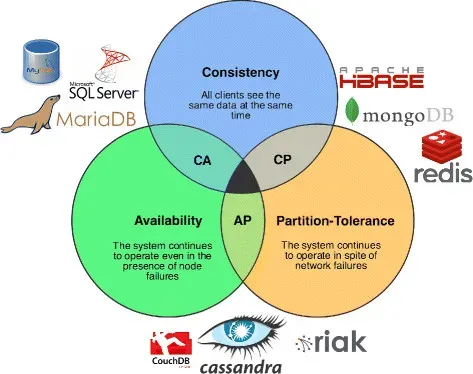
CAP theorem นั้นเกิดขึ้นครั้งแรกเมื่อปี ค.ศ.2000 โดย Eric Brewer โดยระบุไว้ว่าการทำระบบให้บรรลุทั้ง 3 อย่างนั้นไม่สามารถทำได้
แต่สามารถทำให้บรรลุ 2 ใน 3 ได้ ซึ่งทั้งสามอย่าง คือ
- consistency (ความสม่ำเสมอ)
- availability (ความพร้อมใช้งาน)
- partition tolerance (ความทนทาน)
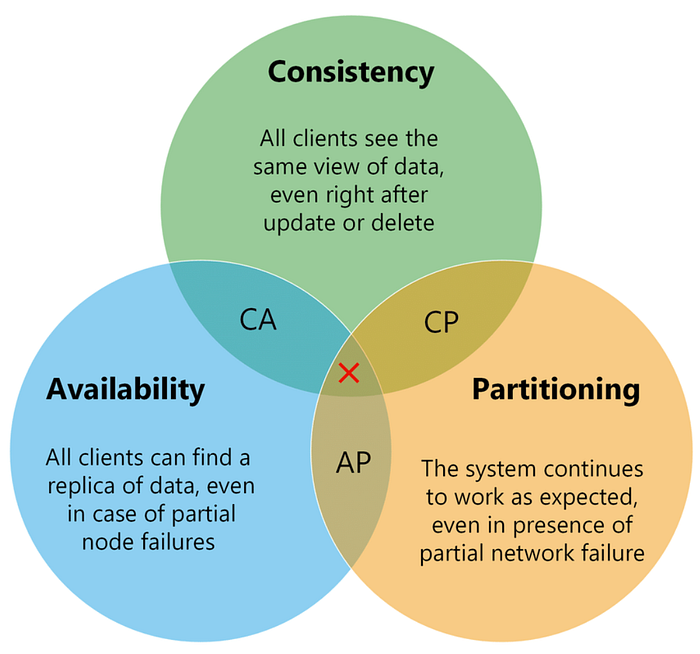
มาลงรายละเอียดของแต่ละตัวกัน
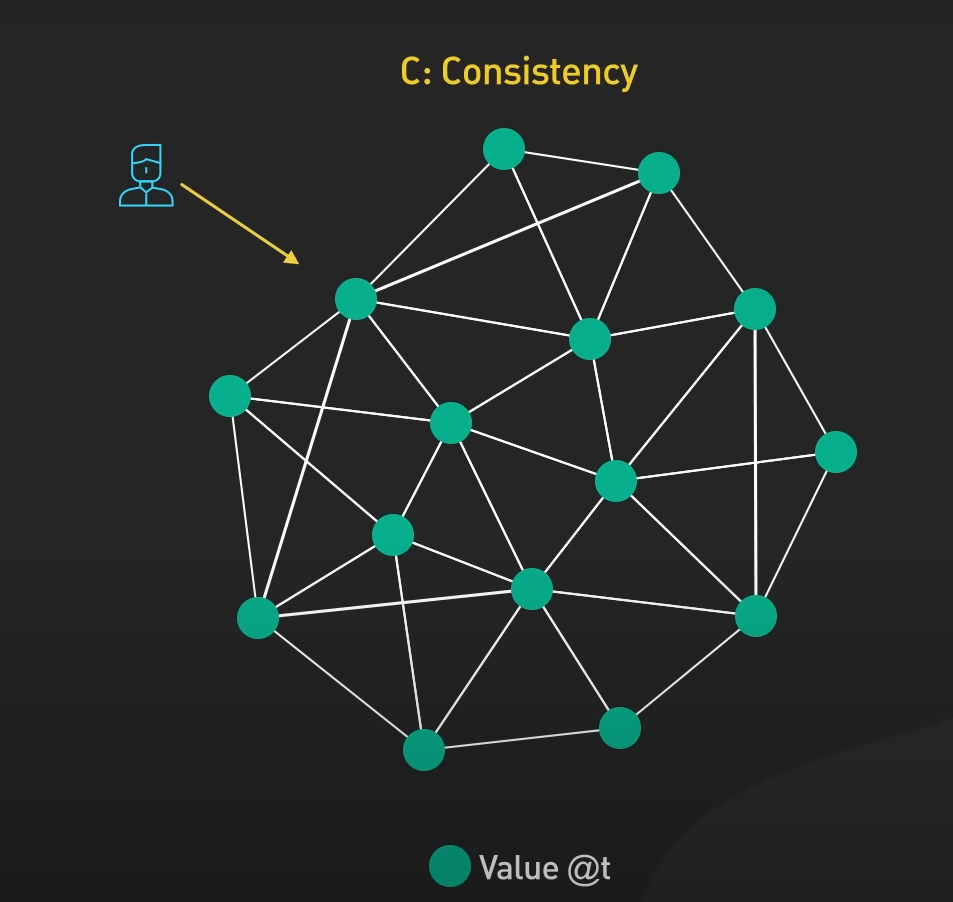
C (consistency)
ความสม่ำเสมอ คือ ทุกโหนด หรือ ทุกอุปกรณ์ในระบบ สามารถเห็นข้อมูลที่เป็นข้อมูลล่าสุดเสมอ
ซึ่งการทำให้ระบบมี consistency สูงนั้น เหมาะสำหรับระบบที่ต้องการความสมบูรณ์และความถูกต้องของข้อมูลเป็นสิ่งสำคัญ
แต่การได้มาซึ่ง consistency นั้น แลกมากับการใช้เวลาและ availability ที่ลดลงนั้นเอง
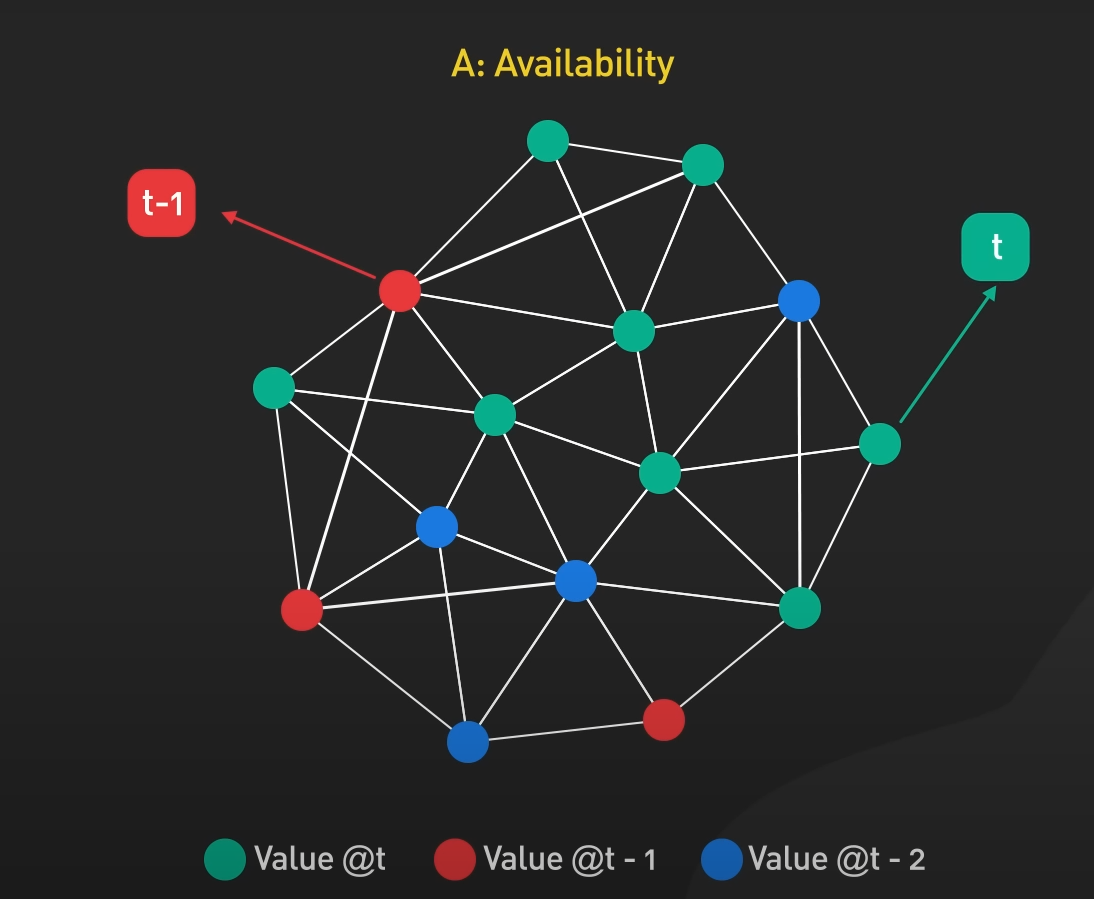
A (availability)
ความพร้อมใช้งาน คือ มีความสามารถในการให้ข้อมูล แก้ไขข้อมูล แก่ผู้ใช้งานอยู่ตลอดเวลา ถึงแม้ว่าจะมีโหนด หรือ อุปกรณ์บางตัวไม่สามารถใช้งาน หรือ ให้บริการต่อได้ก็ตาม เพื่อให้ผู้ใช้สามารถใช้บริการได้ต่อเนื่อง
ซึ่งการได้มาของ availability นั้น แลกด้วย consistency ที่ลดลง
P (partition tolerance)
ความทนทาน คือ ระบบสามารถทำงานต่อได้ และ พร้อมใช้งาน แม้จะมีโหนด อุปกรณ์ หรือเครือข่ายไม่สามารถเชื่อมถึงได้ client จะยังเข้าถึงได้อยู่
ความทนทานนั้นเป็นสิ่งสำคัญในระบบ เนื่องจากทุกระบบอาจเกิดปัญหาได้ทุกเมื่อ และ อาจเกิดได้จากหลายสาเหตุ ดังนั้นเราจึงจำเป็นต้องให้ความสำคัญกับเรื่องนี้ด้วย
วิธีการใช้งาน
จากที่ได้บอกไว้ตั้งแต่ตอนต้น CAP theorem นั้น สามารถทำให้ระบบมี 2 จาก 3 ข้อได้ ซึ่งรูปแบบที่เป็นไปได้ คือ 3 แบบนี้
CP (consistency + partition tolerance)
ระบบที่ให้ความสำคัญ กับ ความถูกต้องของข้อมูลทั้งระบบ
เมื่อมีการเขียนแก้ข้อมูลในระบบ ระบบจะทำการ sync กับทุกโหนด หรือ ทุกอุปกรณ์ให้มีข้อมูลเดียวกัน
แต่เมื่อเกิดปัญหา เช่น network ล่ม, อุปกรณ์ขัดข้อง จนเกิดเป็นระบบย่อยหรือที่ เรียกว่า partition
ระบบจะไม่ยอมให้ผู้ใช้มาใช้ระบบได้ จนกว่าจะมีการซ่อมหรือกู้ network กลับมาจนเป็นปกติ ถึงจะเปิดให้ใช้งานอีกครั้ง
นั้นก็ คือ การเสียความสามารถในการใช้งาน หรือ availability ไปนั้นเอง แต่บางระบบยังสามารถให้ดูข้อมูลได้อยู่ แต่ไม่สามารถแก้ไขได้
AP (availability + partition tolerance)
ระบบที่สามารถเขียนและอ่านได้ แม้จะเกิด partition ขึ้นบนระบบ
แต่มีข้อเสีย คือ ข้อมูลบางข้อมูลไม่ได้เป็นข้อมูลล่าสุดเสมอไป ดังนั้น เมื่อระบบกลับมาเป็นปกติ จะต้องทำการ sync ข้อมูลใหม่ ให้กับโหนดที่ไม่ได้รับข้อมูล
ตัวอย่าง ระบบ AP คือ DynamoDB, Riak ของ Amazon
CA (consistency + availability)
ระบบที่สามารถ sync ข้อมูลได้เลยทุกโหนด เมื่อมีการแก้ไขข้อมูล เพื่อความสม่ำเสมอและพร้อมใช้งานในทุกโหนด
แต่มีข้อเสียข้อใหญ่ คือ เมื่อเกิดการ partition ขึ้นในระบบ มันจะทำให้ CA ไม่สามารถใช้งานได้ จนกว่าจะมีการซ่อมแซมหรือกู้คืนมา
ตัวอย่าง ระบบ CA คือ Spanner ของ Google